September 13, 2025
There have been lots of people sharing different AI agent architectures recently so I thought I’d share how we’re using them at Positive Sum in production to help us do private markets research across hundreds of gigabytes of data. We tried a few dedicated agent frameworks, but found the abstraction levels didn’t feel quite right for our use case so we rolled our own.
The agent architecture we’re using is called the evaluator optimizer pattern (“EO”). Simply put, two LLMs recursively work together to generate the highest quality answer possible. One LLM is used to generate answers and another to evaluate the answers. If the evaluator fails the generator’s response, it gives feedback why and regenerates an answer until it passes. I originally got the idea for this from an article I read in a blog post written by Christian Tzolov from Spring in the Fall of 2024. It seemed a useful approach and a good place to start building from so I decided to run with it.
Here's the original architecture diagram from Spring article:
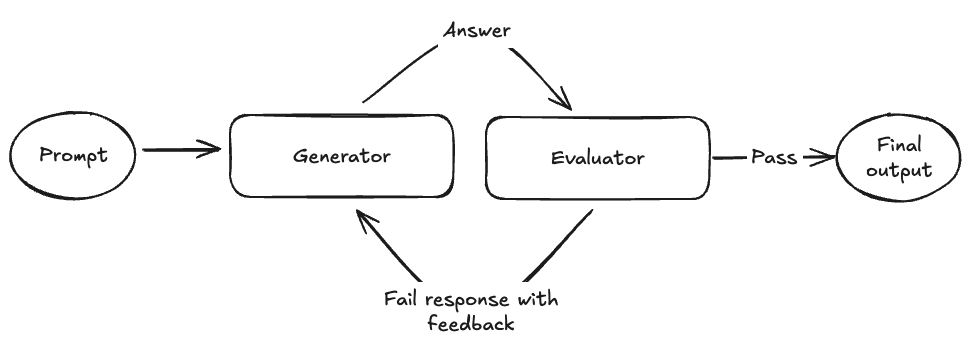
The architecture is generally straightforward, but there are some meaningful optimizations our team at Positive Sum has made since initially deploying it:
- A ledger (memory construct) that tracks generations, evaluations, and every action taken for every task. The generator and evaluator have read/write access to it at runtime.
- Plan generation and plan updating
Updated architecture diagram:
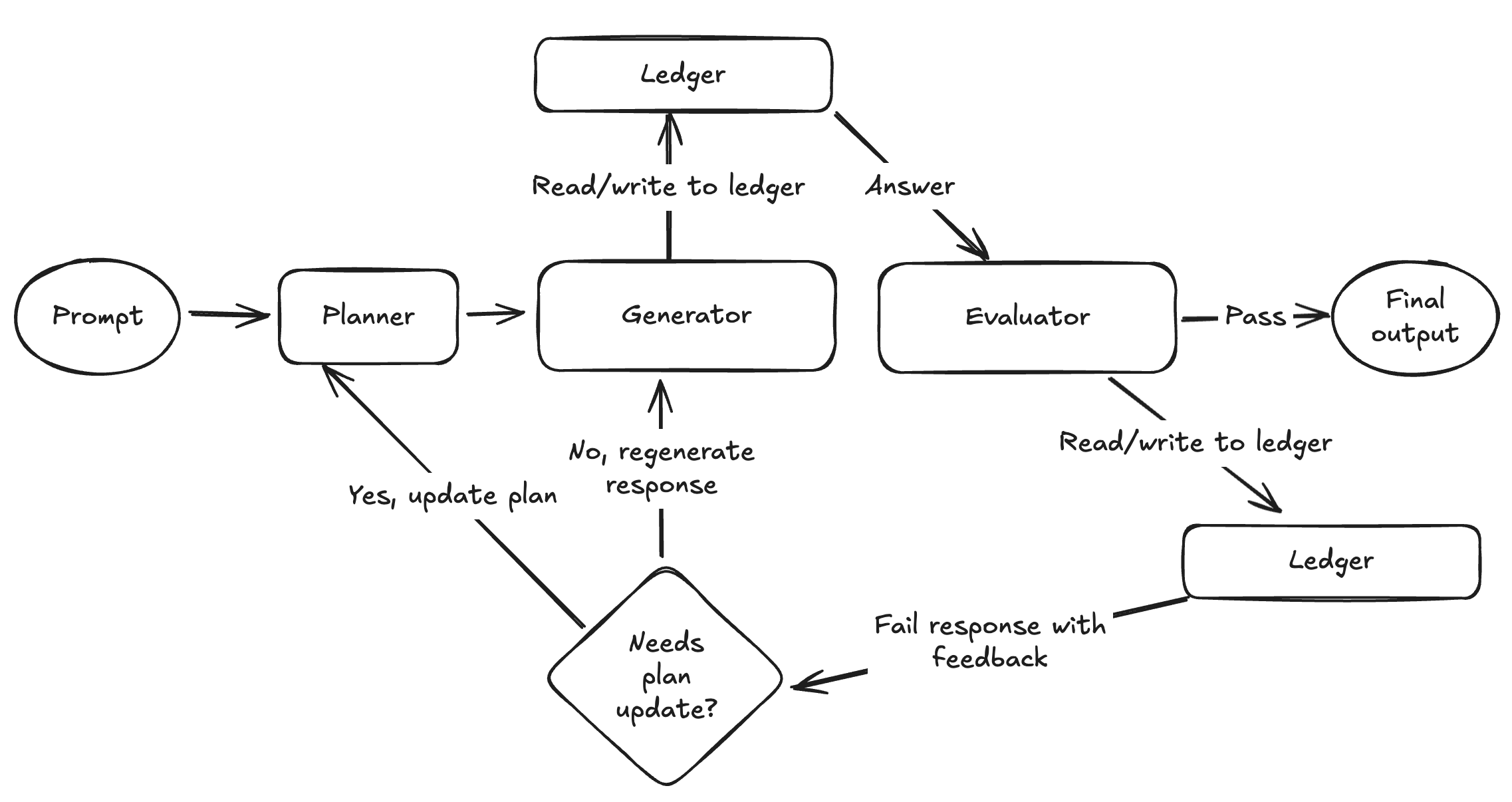
Below, I’ll cover in detail each addition we’ve added to the evaluator optimizer agent pattern.
Ledger (Agent Memory)
The ledger is the most important addition we’ve made to the EO agent loop. It’s essentially a memory construct that contains an action log of things the agent did for a given task: output from the generator and its corresponding evaluations, tool calls and their parameters, and externally retrieved data from various sources like our vector store or the web. What this enables is full transparency into the agent’s working memory while it’s completing a task, and it gives the agent the ability to read through the ledger at various points in the EO loop. Additionally, at each key action point in the EO loop, the agent writes important data into the ledger that it can reference later. The ledger is formatted for LLMs using markdown.
Here's a sample from the ledger when I asked the agent to compare the state of CUDA vs ROCm in 2025:
Searched for relevant expert insights with query: CUDA advantage over ROCM.
I added the results from this to the action log.
Search Results:
<knowledge type="type">knowledge...</knowledge>
Searched Web for relevant information with query: ROCM status and comparison with CUDA in 2025.
I added the results from this to the action log.
Search Results:
<knowledge type="type">knowledge...</knowledge>Note, items get added to the ledger each time after the generator or evaluator produces a response. Two plan steps had been executed at this point and the ledger contains a list of information with what tool was called and with what query, and it also includes the search results from each tool call.
The ledger greatly increased the overall answer quality the agent was producing. The downside is for long running research tasks that call multiple tools and ingest a lot of data, the ledger size can grow, and that introduces some overhead in order to make sure we’re staying under context limits for various LLMs used in the EO loop. To deal with that, we have a context pruning step that runs before each LLM call, both generations and evaluations, where we selectively prune data out of the ledger based on factors such as how recently the data was added to the ledger and what type of data it is. There are other optimizations we could make here like compressing data in the ledger via summarization or other means, but we haven’t got there yet.
Planning
Planning and plan updating are important capabilities in every agentic AI system. Inevitably, LLMs can veer off course due to poor instructions, lack of context, too much context (I own contextrot.com if anyone’s interested in buying), and many more reasons. A strong initial plan lowers the chances an LLM will falter on complex tasks like market research diligence. And the ability to update a plan midway through a task is necessary when new information is learned from previous steps that change the problem solving strategy for a specific task. For example, the agent may learn that its search query provided to a tool call yields no results from our data corpus, and it needs to adjust its plan by searching for something completely different or over a different time period.
In the EO loop, generating a plan is the first thing we do when the user sends our agent a research task. Plan generation uses its own dedicated system prompt with a set of tight instructions on plan requirements such as plan style and what tools are available to use.
Here's a sample plan when I asked the agent the same question about CUDA vs ROCm.
Plan:
1. Searching for expert insights on the advantages of CUDA over ROCM, focusing on expert opinions and industry trends.
2. Using retrieved information to summarize the advantages CUDA has over ROCM based on expert insights.
3. Searching through various credible sources to find current information and updates on ROCM as of 2025, with a focus on its features and competitive standing against CUDA.
4. Using gathered information to compare ROCM's current status in 2025 with CUDA, focusing on performance, adoption, and technological advancements.
5. I will use the action log to produce a document that is highly readable and explicitly addresses the objective.An individual tool call like searching across some dataset for RAG almost always gets a dedicated step in the overall plan. Based on its system prompt, the agent knows how to map the language in each step above to the correct tool call. We’ve found that combining tool calls and information synthesis into the same plan step results in a higher failure rate from the evaluator, so we break these into discrete steps. Generally, it’s good practice to keep LLM tasks as discrete as possible (as with most things in software) to avoid drifting off course. Lastly, we always artificially append a formatting and writing style step to the end of the plan.
A typical plan for an investment research task has anywhere from 3 to 10 steps, sometimes more. The plan generator returns a list of plan steps which are saved to our database for future interactions by the agent.
The agent then iterates over each step using the EO framework while aggregating its results from each step into the ledger. We saw a step change improvement in answer quality after implementing a planning step, but the agent would still occasionally back itself into a corner if its original plan didn’t yield results that passed the evaluator. We decided it would be interesting to give the agent the ability to update its original plan if it hit a failure threshold for a specific plan step. Plan updating can also be triggered if the agent gets access to new information from a previous step that would change how the agent approached solving a problem.
When plan updating is triggered, it preserves all successfully completed plan steps, and generates new steps from the step that failed and on. This ensures we keep any steps that already produced a good response, and tack on the newly generated plan steps. During a plan update, the agent has read access to the ledger, which allows it to more accurately adjust its plan because it can see into its own working memory for the overall task at hand. This helps the agent to avoid generating plan steps that already led to poor results. The ledger acts as an insurance policy here. Similar to the old adage “show me where I die so I don’t go there” except modified to “show me what I’ve already tried so I don’t try it again.” The agent can see what it already tried and how that was evaluated so it doesn't make the same mistakes. After updating its plan, the EO loop repeats itself. We cap plan updates to some reasonable threshold before killing the EO entirely so the agent doesn’t get stuck in a forever loop.
Final Thoughts
Overall, the EO loop has served as a nice starting point for the research platform we’re building at Positive Sum. We throw all sorts of different tasks at it like helping us write investment memos, searching across expert interviews, reading through documents shared with us by potential investment opportunities, and even to pull out relevant excerpts from thousands of our internal slack conversations. We’ve spent a reasonable amount of time optimizing it but there’s still plenty of low hanging fruit to pick.
Thanks to my coworkers Donald Lee-Brown and Terran Mott for their contributions to our EO framework, to Vishnu Bashyam for providing feedback on this post, and to Christian Tzolov who was the original author of the Spring blog post that introduced me to the EO pattern.